

Explore
Explore the world of Performics
of Performics.
Insights
News
Events
Performics Poland Earns EMMA Recognition
Congratulations to our team at Performics Poland for taking home the EMMA Media Marketing Polska (MMP) Award in the Channel Excellence – Social Media category for the “Blink Twice If…”…

Performics India Wins Through Connected Marketing
Congratulations to Performics India on securing two wins at the ET Brand Disruption Awards for airtel — recognition that highlights how data, MarTech, and performance innovation can combine to create…

SEO & Generative Engine Optimization GEO
A Performics LATAM Session Our Performics LATAM team hosted a fantastic workshop on SEO and Generative Engine Optimization (GEO)—creating a space to explore one of the biggest opportunities in digital…

Performics Middle East Talent Named in Agency Faces to Watch 2026
Performics celebrates two standout talents, Jad Matta and Alessandro Bettolini, for landing on Campaign Middle East’s Agency Faces to Watch 2026. Jad is recognized in the Creative Faces to Watch category, while…

Connected Identity: The Performance Multiplier for Modern Search Marketing
Executive Summary Connected Identity strengthens Search by expanding matchable audiences, improving thequality of platform learning signals, and enabling precise lifecycle segmentation. Brandsthat embed identity through Publicis Groupe’s Connected Search program…

Rethinking Conversion Rate Optimisation as a Long-Term Growth Discipline
Many brands approach Conversion Rate Optimisation (CRO) with unrealistic expectations. They believe CRO works like an instant performance booster, a single intervention expected to deliver overnight gains and dramatic uplifts….
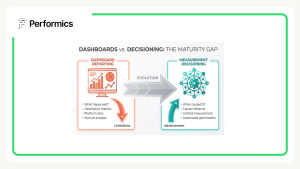
Beyond Dashboards: Building Measurement That Drives Decisions
Most marketing organisations today operate with sophisticated dashboards. Real-time metrics, elegant visualisations, executive summaries. On the surface, everything appears under control. Yet beneath the green arrows and upward curves lies…